

4 Radnor Corporate Center
Suite 350
Radnor, PA 19087
+1 (888) 507-2270
Blog
SEND Dataset QC: Best Practices & Recommendations
On April 18, Senior Product Management Director Peggy Zorn delivered an information-packed presentation on best practices and recommendations for SEND dataset review and visualizations.
SEND datasets have become an integral part of the review, analysis, and interpretation of nonclinical toxicology studies, and this will trend will only continue to grow. The SEND dataset creation process is challenging and often requires a combination of data integration and manual effort, making quality control a critical step to ensuring that SEND dataset packages are fit for use.
What is SEND?
SEND is the Standard for Exchange of Nonclinical Data, a CDISC standard based on the SDTM model. It covers the study design and individual animal data for in scope nonclinical study types.
Like SDTM datasets, SEND datasets are produced in SAS transport or XPT format. The current versions of the SEND standard in use at FDA are SEND 3.1 and 3.1.1, SENDIG-DART Version 1.1 for reproductive toxicity studies, and SEND-AR version 1.0 for Animal Rule Studies. In this article, we will focus primarily on SEND 3.1 and SEND 3.1.1.
SEND datasets are required for single-dose, repeat-dose, carcinogenicity, cardiovascular, and respiratory safety pharmacology, embryo-fetal development and animal rule studies with start dates after those published in the [FDA Data Standards Catalog]. SEND is required by both CDER and CBER.
The requirement for CBER has just taken effect and SEND datasets are now required for in-scope studies and data types for studies starting after March 15th, 2023.
When are SEND datasets created?
Currently, most studies requiring SEND datasets for FDA submission are for regulatory submissions where timelines are tight.
- In progress: Work may begin on SEND data creation while the study report is still in draft, so it is important that changes are propagated to the datasets as changes are made to the data. This involves coordination across departments - and even test sites - if some data is coming from a location other than the test facility.
- Current studies: SEND datasets for current studies are generally produced by the test facility at the time of study report finalization when SEND datasets are required for submission to the FDA.
- Retrospective: Sponsors use SEND as a data exchange and transmission format for feeding internal databases and data warehousing environments. SEND datasets can be created retrospectively for completed studies where it was unknown they would be needed. In this case, SEND datasets are created from the study report tables when electronic source data is not available.
Determining the level of QC needed
Considering the level of QC needed for some datasets, it's also important to understand how they were produced. For instance, more QC is needed if all datasets were created manually from a PDF study report than if the data was output from a data collection system.
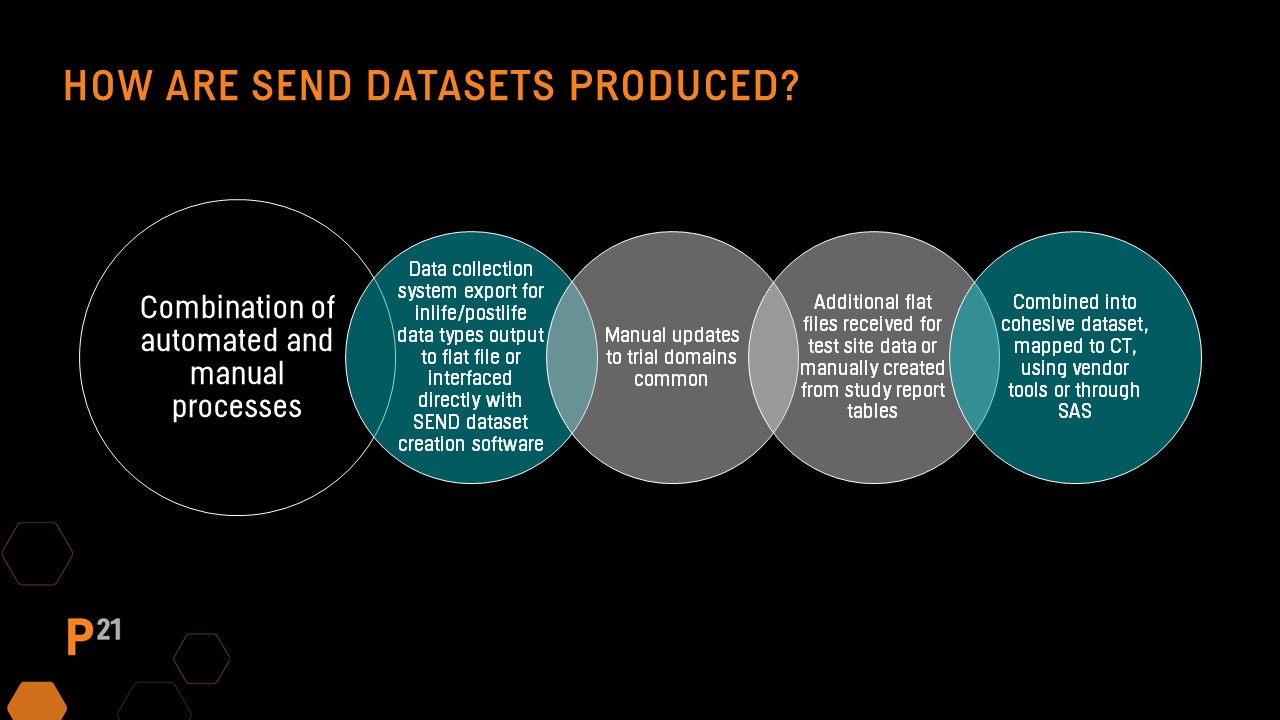
QC needs: SEND datasets from a CRO of third party
SEND datasets are often produced by CRO test facilities or a third-party specializing in SEND dataset creation. They are passed to the sponsor for inclusion in the regulatory submission, so it's important the sponsor understands how the datasets were created and any QC applied to determine additional review needed.
QC needs: SEND datasets’ intended use
The level of QC needed on SEND datasets can vary based on their intended use. For datasets included in an FDA submission, data standard and FDA technical conformance guide conformance is expected. SEND datasets intended only for sponsor use in a data warehouse environment may have different requirements.
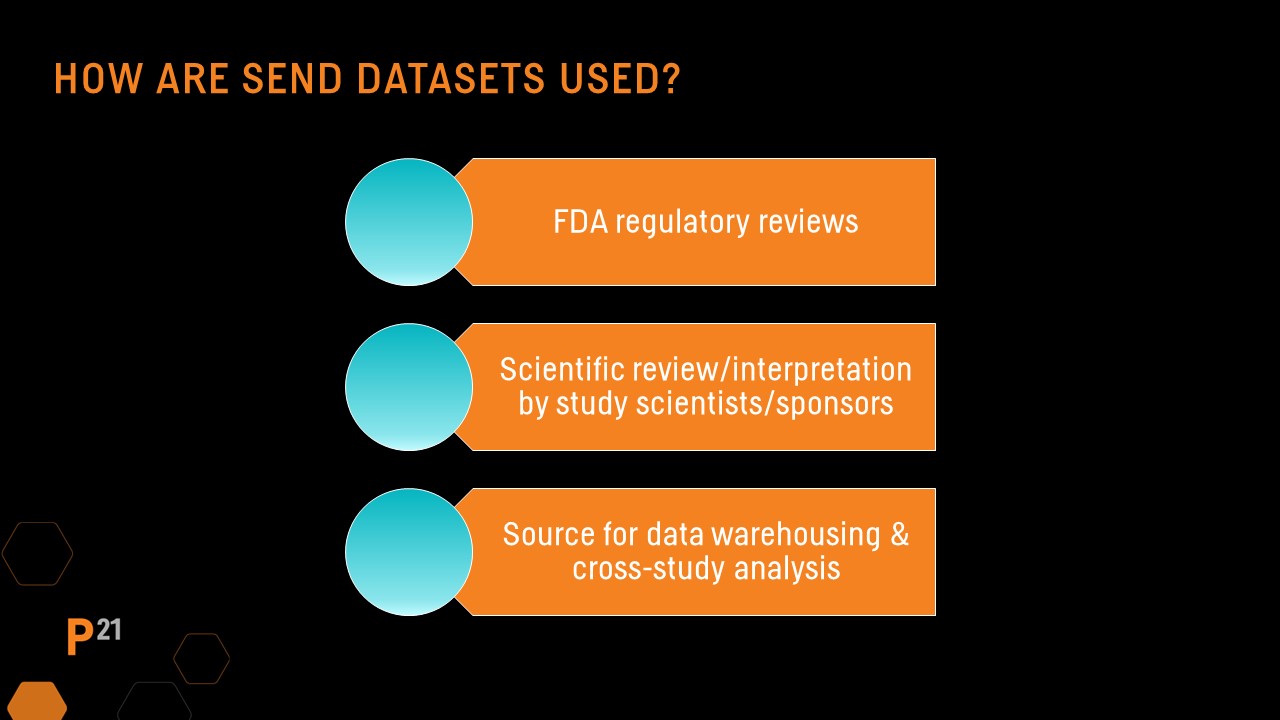
Why Quality Control is so important
Why are QC processes so important in this age of automated systems and software? SEND datasets are created using a combination of automated and manual processes. In most cases, an integration of data from several sources is usually required.
Trial domains are often created manually, and the SEND dataset creation process may originate from the PDF Study Report file. During the creation process, study report tables and dataset output are often compared to ensure alignment, and errors are often discovered.
Define.xml and nsdrg files are also created using a combination of automated and manual processes that must be synchronized when dataset changes are made after initial creation. Often CRO's or other third-party vendors responsible for SEND dataset creation perform part of the initial QC before data is passed to the sponsor for inclusion in a regulatory submission.
Because of these factors, robust quality control is essential to ensure high quality SEND datasets for regulatory and scientific use.
The FDA Technical Conformance Guide emphasizes the need for strong and systematic dataset QC practices in two sections: Section 8.2.2, which indicates sponsors should evaluate against conformance rules prior to submission, and Section 8.3.1, where the importance of traceability between the study report summary and individual data tables and the datasets is established.


The FDA routinely presents information to the nonclinical community regarding quality issues with SEND datasets, highlighting issues that most interfere with submission reviews, through several channels:
- Small Business and Industry Assistance (SBIA) webinars
- CDISC SEND team meetings
- Fit for Use Pilot feedback
- FDA Technical Rejection Criteria presentations
PHUSE White Paper: SEND Dataset QC Best Practices
The PHUSE Nonclinical Working Group investigated QC practices companies use for SEND datasets and produced a white paper and poster presented at the most recent PHUSE Computational Science Symposium meeting.
The team outlined results from a survey of nonclinical group members in the PHUSE network. While the majority of the 51 respondents were from the US, feedback was also received from the CDISC Japan User Group to provide a more global perspective.
The PHUSE Nonclinical Working Group sub-team identified six major areas that characterize high quality datasets that include:
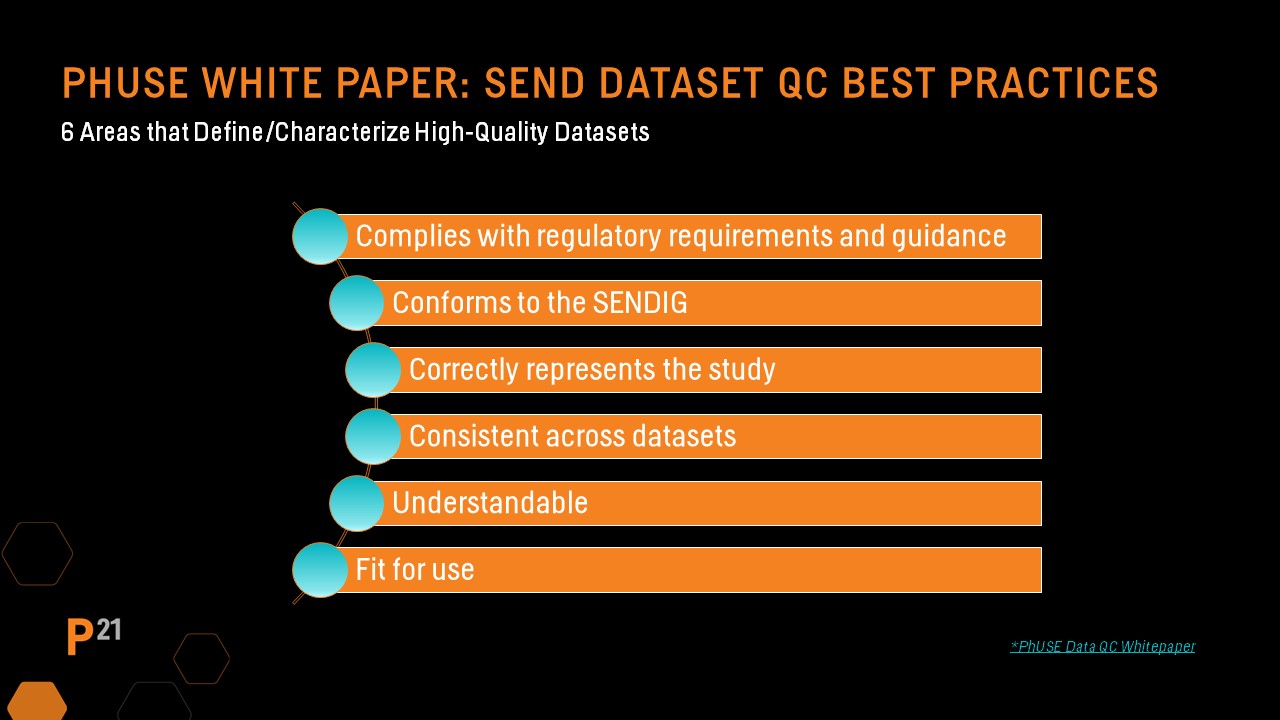
These areas are important to keep in mind when developing SEND dataset QC approaches and processes.
Achieving compliance with SEND Standards
SEND dataset QC is a major issue for dataset creators and a priority for SEND consumers, including the FDA. First and foremost, however, SEND datasets must comply with technical specifications in the SEND Implementation Guide. The FDA currently accepts SEND 3.1 and 3.1.1 for general toxicology and cardiovascular and respiratory safety pharmacology studies, SEND-DART 1.1 covering embryo-fetal development studies, and SEND-AR 1.0 covering animal rule studies.
The SENDIG 3.1 IG provides a list of items that must be met to achieve minimal conformance, and these are applied to all versions of the SEND standard. They focus on:
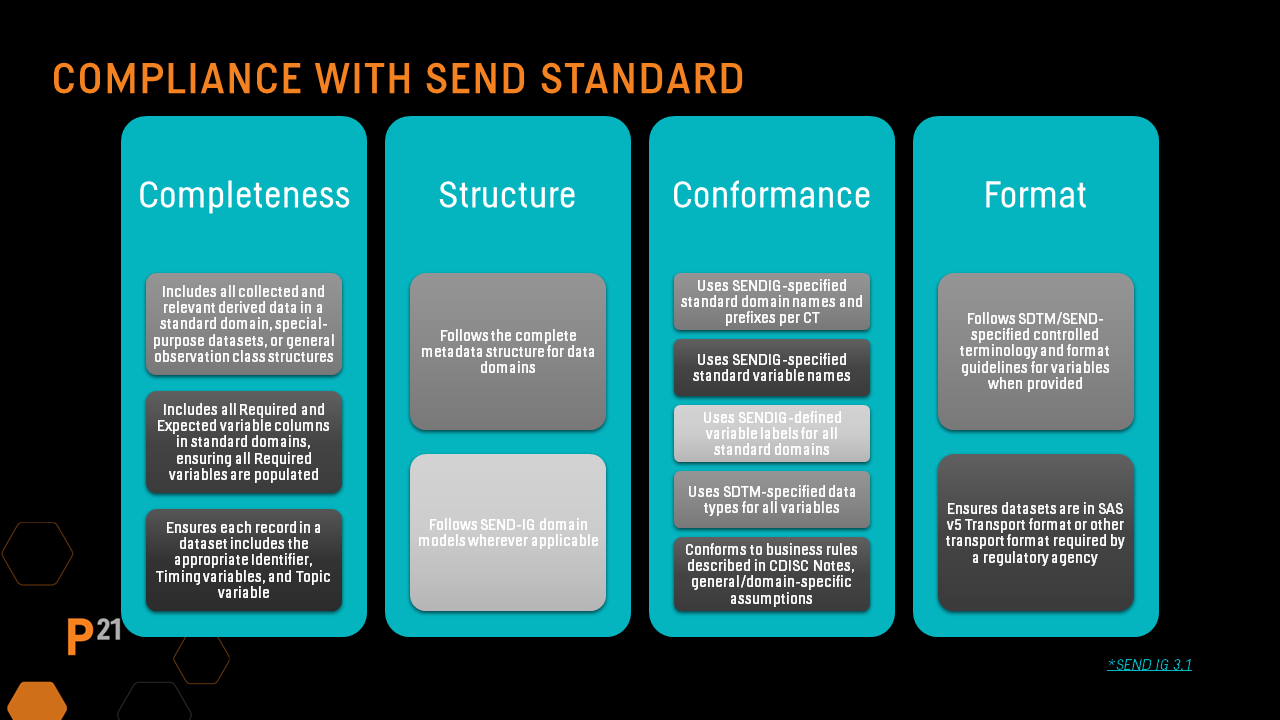
Compliance with regulatory standards
In addition to being SEND-compliant, datasets should also conform to published FDA guidance documents:
- FDA Study Data Technical Conformance Guide - includes dataset-specific recommendations and detailed information regarding requirements for placing datasets correctly within an electronic common technical document (CTD) submission.
- FDA Technical Rejection Criteria - Guidance which, when requirements are met, will allow submissions containing standardized study data to be processed automatically through the FDA Electronic Submissions Gateway.
- FDA Data Standards Catalog - a spreadsheet containing all past and current electronic data standards, including details on which versions are currently accepted at which centers, dates when requirements begin and end, submission types, controlled terminologies, and more.
Both the FDA and CDISC have published rule sets for SEND datasets largely based on information in the SENDIG’s, the Study Data Technical Conformance Guide, and other associated FDA guidance documents related to electronic submissions. These rules form the basis of checks included in automated validator tools available for use with SEND datasets.

It is important to make sure that the automated validator tool you choose has coverage for all items on this list.
Alignment between the Study Report and individual data
The final Study Report serves as a comprehensive and definitive source of information for nonclinical studies and includes both summary and individual data listings for all data collected and analyzed.
SEND datasets associated with nonclinical studies should align with the information and data included in the study report wherever possible. The importance of this alignment is discussed in the FDA Study Data Technical Conformance Guide and was the guiding premise for the work done by the PHUSE Nonclinical Working Group that examined SEND dataset QC practices.
There are five key areas of alignment between the study report and SEND datasets that should be included in any SEND dataset QC process:
- The study design outlined in the study report or protocol should align with the trial design domains.
- All data types included in the study report in scope for SEND should have associated datasets.
- Study report individual data tables should align with the corresponding dataset content.
- Unscheduled or unplanned events must be represented correctly.
- SEND datasets must allow FDA reviewers to replicate data summarizations included in the study report.
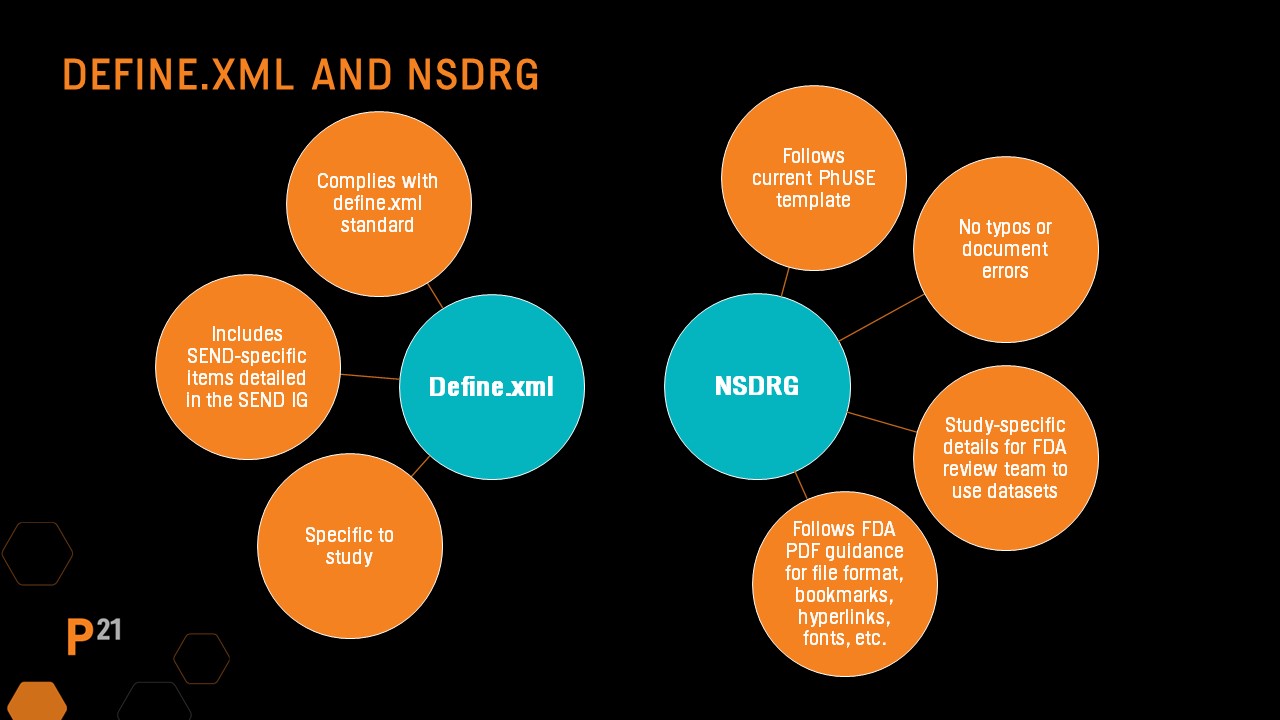
In addition to SEND dataset QC, the required define.xml and nsdrg must also have QC processes applied.
Quality Control processes and tools
Let’s look at some best practices for process development and use of software and automated tools to help make QC of SEND dataset packages easier, more consistent, and produce the best possible product for SEND consumers.
In developing an overall QC process for SEND datasets, there are several key areas of focus:

It is important to ensure that QC occurs at various milestones throughout the SEND dataset creation process. Keeping detailed records of issues identified, changes made, and copies of validation reports from defined review cycles is recommended so that final review of the dataset package can flow smoothly.
Tech tools for review and validation
Automated validators
Automated validation checks are a critical piece of SEND dataset and define file QC, so choosing the right tool for your needs is key. Validation tools should provide comprehensive, realistic coverage and output issues in a logical, understandable way that links to the associated rule.
When it comes to SEND validation tools, look for specific features/functionality:

SEND review tools
It can be challenging to review, QC, or even open SEND datasets if you don’t use a review tool specifically optimized for the SEND format. Tools such as the SAS universal viewer in Excel can help, but SEND-specific review tools often contain robust sorting, filtering and query options, as well as displays specifically designed to facilitate QC, such as tabular summary tables with flexible grouping and display options. SEND-specific review tools also provide links to related records.
Some dataset creation tools output formats such as CSV, XLSX, and XML in addition to the XPT format, but using Excel for QC can be time consuming, tedious, and ineffective. SEND-specific review tools have essential features that boost the effectiveness of QC tasks.
SEND review tools should have advanced filtering, sorting, and column management features. Being able to filter and sort across an entire dataset to look for anomalies, missing data, and data inconsistencies is key to any dataset QC process, as is the ability to group results and summarize data.
Tools that allow easy linking between related domains make QC much easier because comparisons between the study report and the datasets are a key component of dataset QC. Review tools with flexible reports and data presentations that allow for easy comparison to study report tables for checking means, ends, and standard deviations are critical.
Advanced SEND review tools include features such as the ability to generate CTD tables and access to data visualization displays that allow scientists to interactively use and interrogate study data to find trends and patterns within and across data types.
Manual QC processes
Even with the assistance of automated review and validation tools, some checks still must be performed manually. In this case, it’s important to pay particular attention to the following recommendations:

During the SEND dataset QC process, the define.xml and nsdrg files should also be part of the review. If these files are automatically generated by a validator or SEND review tool, the QC process will be simpler and can focus on portions of the files that were updated manually.
Define file manual QC
Define file QC should always include running an automated validator tool, then reviewing and resolving any issues found. The SEND Implementation Guide has recommendations for updates to several key areas in the define file based on the study. Manual updates made to the define file are likely study-specific, so it should be a focus during QC. In addition, spot-checking that hyperlinks to the nsdrg are present and functioning is recommended.

nsdrg file manual QC
Be sure the file follows the PHUSE nsdrg template and all sections are populated correctly. Check the table of contents has been updated and that no errors are present. As with the define file, the nsdrg’s content should be study-specific, and the final nsdrg pdf should follow the requirements included in the FDA pdf specification guidance documents.
SEND Dataset QC: Webinar Q & A
Q: What about aCRF? Is it available for data collection, and do we annotate and submit it?
A: There is no CRF or annotated CRF used in nonclinical studies and is not included in SEND.
Q: What are all the components of a SEND submission package?
A: SEND dataset packages contain SEND datasets for data types covered by the SEND Implementation Guides for SEND 3.1, SEND 3.1.1, DART 1.1 and Animal Rule 1.0. SEND datasets for in scope study types (single-dose, repeat-dose, carcinogenicity, cardiovascular and respiratory safety pharmacology, embryo-fetal development and animal rule studies) with start dates after the requirement dates published in the FDA Data Standards Catalog. SEND dataset packages also contain a define.xml and nonclinical study data reviewer's guide (nsdrg).
Q: What about data from sources like spreadsheets, lab reports, and heat maps? Do they all have to go into SEND datasets, or are there times when it is better to just submit the raw data source?
A: When source data comes from multiple sources, robust QC is required. Because the nonclinical study report is included in the submission package and includes individual and summary data and the protocol and study methods, traceability between the study report content and the datasets is a major component of the QC process.
Comparisons are made between the individual and summary data in the study report and SEND data for each domain/data type and any discrepancies reported so that any needed study report amendments or updates to the source data can be accomplished. The study report to SEND dataset comparison can take the form of verification of a sampling of data (e.g. 1 animal per Set per Sex for all data, a percentage of the data such as 5 or 10%).
If significant manual work was done to create the SEND datasets, a 100% review against the study report tables may be required. In-scope study types (single-dose, repeat-dose, carcinogenicity, cardiovascular and respiratory safety pharmacology, embryo-fetal development and animal rule studies) with start dates after the requirement dates published in the FDA Data Standards Catalog must contain SEND datasets for data types covered by the SEND Implementation Guides for SEND 3.1, 3.1.1, DART 1.1, and Animal Rule 1.0.
About Peggy Zorn
Peggy has a deep background in nonclinical data management warehousing in the SEND Standard, including serving as lead of the CDISC SEND Controlled Terminology team for more than seven years, and continues to be involved in the CDISC SEND team as well as the PHUSE Nonclinical Working Group. Prior to joining Certara, Peggy worked for 15 years at Pfizer, with six of those years focused on nonclinical data management and warehousing. She also spent several years at INDS, which is the company that originally developed the SEND Explorer dataset review and visualization tool.
Tags:
Blog Main Page
