

4 Radnor Corporate Center
Suite 350
Radnor, PA 19087
+1 (888) 507-2270
Blog
New PMDA Validation Rules 3.0 Explained
On December 15th, 2021, the Japanese Pharmaceutical and Medical Devices Agency (PMDA) published its long-awaited update to the Validation Rules for SDTM, ADAM and Define-XML. PMDA Validation Rules 3.0, aka PMDA Engine 2010.2, introduced additional standard conformance rules from CDISC, support for ADaM-IG 1.1, and many other changes.
Seiko Yamazaki, authorized CDISC ADaM trainer and Pinnacle 21 Consultant, took us through what you need to know about this update in our recent webinar. Below are some additional key points, as well as answers to related questions from our attendees.
Choosing an Engine Version
The PMDA performs independent validation of your study data in their P21 Enterprise environment and reconciles their results with the results and Explanations of the sponsor. Using the same Engine that the PMDA will use is the best way to de-risk the review process. Discrepancies can cause delays in the submission and approval timeline, or even rejection.
Q: Can I use different PMDA Engine versions, such as Legacy Engines, for different studies in the same application? When will PMDA Legacy Engines be deprecated?
A: The PMDA allows only one Engine version (i.e., Validation Rules version) to be selected per application.
- In the PMDA’s GATEWAY web system, it is not possible to select different Engine versions for different studies in the same application. E.g., if you use PMDA Engine 2010.2 in your first submission for an application, then you should use that same PMDA Engine 2010.2 for all future studies associated with that application, for its entire lifecycle, even if new PMDA Engines are released thereafter.
- PMDA Legacy Engines are maintained so that sponsors and the PMDA both can revalidate with the Engine version in effect at the time of initial application. After it is safe to do so, very old versions, such as PMDA Engine 1511.6, will be totally deprecated—exact timing to be determined later.
Engine Release Timing & Content
As of as of 2021-Q4, we deployed PMDA Engine 2010.2 to the PMDA and to the users of P21 Community and Enterprise. We covered the main highlights previously in our blog post: P21 Releases New PMDA Validation Engine.
Q: How can I access PMDA Engine 2010.2? It is released to general availability?
A: Yes, it is now released to general availability. Explore it in all P21 products:
- When you log in to P21 Community 3.0.0 and higher online with your PinnacleID, you will see the new PMDA Engine 2010.2 present as an option in the Validator.
- In P21 Enterprise 4.0.0 and higher, it is present on each Data Package Configuration page. Also, with P21E you can revalidate datasets from PMDA 1810.3 (Legacy) to PMDA 2010.2 and automatically compare/reconcile any differences, as well as generate a PMDA-specific Reviewer’s Guide.
Q: Which Validation Rules changed in PMDA Engine 2010.2, especially those related to ADaM-IG 1.1?
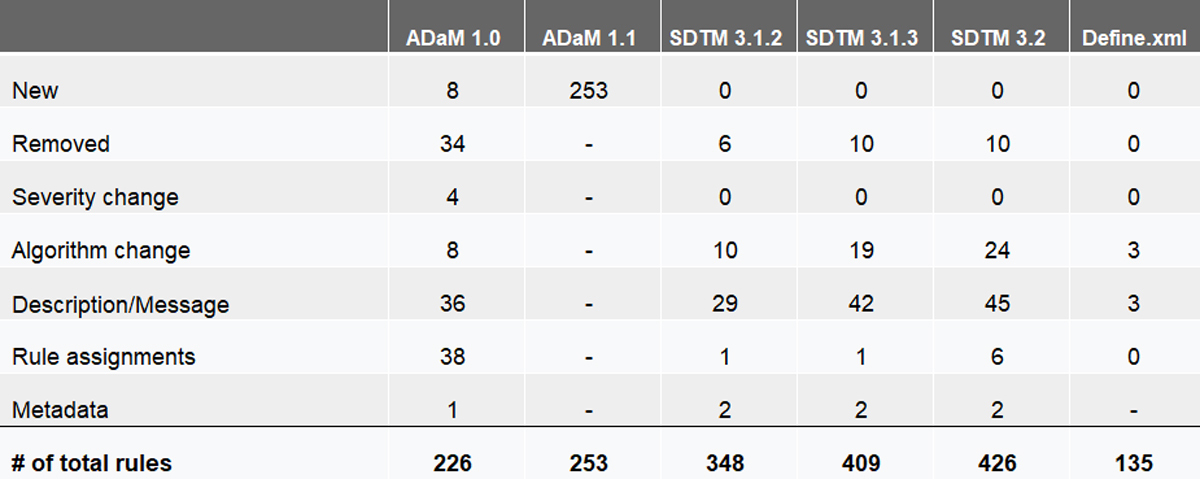
A: The PMDA has published this information: Study Data Validation Rules Version 3.0. The biggest changes are the 8 new Rules for ADaM-IG 1.0 and 253 new Rules for ADaM-IG 1.1. The chart below provides a breakdown of new rules, removed rules, algorithm changes, and more.
Q: In P21 Enterprise, is the P21 Engine simply the latest PMDA and FDA Engines combined?
A: Yes and no. The P21 Engine aims to be a superset of the most recent Validation Rules, regardless of agency.
- In addition to being the only Engine that supports custom standards and terminologies, the P21 Engine is also unique in that, when the FDA and PMDA have different algorithms for the same Rule ID, the latest (more recent) algorithm prevails.
- Note: To prevent delays during regulatory review, it is always best to perform your final (or nearly final) pre-submission validation with the Engine specific to that agency, and reflect any Issues found into the xDRG for that agency.
Fixing Reject Issues
If Issues with Severity of Reject are found in your validation results, the PMDA's review will be suspended until the Issues are fixed. The PMDA’s review will also be suspended if corrupt files cause the validation itself to fail.
- The PMDA accepts submissions if and only if they find no Reject issues or validation failures. The PMDA runs validations on your datasets using their instance of P21 Enterprise—the same tool available to clients for managing and validating clinical trial data. Its Submission Checklist feature helps you ensure all Rejects are fixed well in advance.
- Effective April 2022, the PMDA asks sponsors to submit Form A for Explanation of Error Issues at the Pre-NDA Meeting (formerly, this was done at the Consultation on Data Format of Submission of Electronic Study Data). When the PMDA independently validates data packages and find new/undisclosed Error Issues without Explanations, the PMDA will send inquiries to sponsors to address the discrepancies.
Q: Our submission to the PMDA includes an older study that is showing Reject Issues? Should we submit it as is?
A: No, if you are including older studies in your submission package, all Reject Issues need to be fixed. The same applies to newer studies, too. If you do not fix Reject Issues, there is a high risk of automatic rejection by the PMDA.
Q: In our pre-submission consultation with the PMDA, do we need only the P21 Validation Report with our Explanations for Issues with Severity of Error, or do we need to prepare our complete data package, including XPT files, define.xml, and the Reviewer’s Guide?
A: The latter. To resolve key Reject and Error Issues, you need to prepare and validate a complete data package that includes the needed supporting documents, such as define.xml, the Reviewer’s Guide, and Form A.
Differences between Japan’s PMDA and US FDA
The PMDA submission process is very different from that of the FDA. While both regulatory agencies require validation and Explanations for unfixed Issues, the PMDA instructs that Issues with a Severity of Error that cannot be fixed need to be disclosed to the PMDA via Form A for Explanation of Error Issues at the Pre-NDA meeting. The PMDA presented a process overview in Feb. 2022 (Japanese language only).
Q: Why does the PMDA maintain the Severity category, while the FDA does not?
A: The PMDA still maintains and publishes the Severity category to support their Issue triage and inquiry process. However, the FDA has deprecated Severity altogether, apart from Reject, and now simply requires every unfixed Issue to have an Explanation.
- FDA stopped using Severity because their meanings had divergent interpretations some applicants ignored Warnings. For the FDA, it is important to explain all Issues, it is not true that you need to explain only Errors.
- Though the FDA/PHUSE have retained the Severity column in the xDRG template for now, the completion guidelines state, “If your conformance diagnostics do not include severity, leave that column blank.” The column itself will likely be dropped in the future.
Q: If our data package complies with the FDA’s submission requirements, can we reuse that package as is for the PMDA as well?
A: Not necessarily. The agencies don’t have exactly the same requirements. For example:
- The FDA prefers Conventional Units where the PMDA requests SI units, and the scope of data subject to electronic submission may be different between the PMDA and the FDA.
- Other differences include file naming conventions, TS domain content, and the versions of standards required per each agency’s Data Standards Catalog.
- For details, please refer to the Technical Conformance Guides and the PMDA’s Notification on Practical Operations.
Q: For PMDA submissions, do we need to remove items relating to the SNOMED dictionary from our Trial Summary (TS) domains?
A: No, you may keep items relating to the SNOMED Controlled Terminology (CT) intact, and the PMDA will simply ignore them. Japan is currently not a member country, and thus the PMDA does not deploy that dictionary or run Validation Rules related to it.
Japanese/English Language Encoding
The PMDA’s Technical Conformance Guide and the Q&A on the PDMA website have details on handling language encoding. As a rule, submit to the PMDA datasets consisting of alphanumeric characters only.
Q: If our SDTM datasets include double byte characters, should we correct them?
A: Generally, yes. However, see FAQs on Electronic Study Data Submission item Q4-5 (English, Japanese), for how it depends on your situation:
- If the variables can be translated from Japanese to English your TLFs with no information lost in translation, you may submit English-translated datasets consisting of alphanumeric characters only.
- If some information is lost in translation, you may submit both the datasets with the original Japanese variables in addition to the English-translated datasets.
If we missed any burning questions or topics, check out the full webinar and slide deck to see if we covered it. If you still have other questions, please feel free to contact us!
Tags:
Blog Main Page
