

4 Radnor Corporate Center
Suite 350
Radnor, PA 19087
+1 (888) 507-2270
Blog
SDTM Data Handoffs: Using Biostats Data to Produce Patient Narratives
When looking at the authoring requirements to document trial outcomes, there are numerous documents and reports that need to be written for various reasons. The total number of documents is staggering and takes a large effort by medical writing teams – or even biostatisticians on smaller teams tasked with producing them - to prepare this material.
One such document is the patient narrative. In a large trial, a medical writing team may have to author 200-400 patient narratives, each of which can each be several pages in length and contain numerous data points. The average time to produce one narrative is up to 4 hours. A large study with 400 narratives can take up to 1,600 hours with little-to-no flexibility in project timelines.
The basics of understanding patient narratives
So, what is a patient narrative, exactly? It’s a summary describing serious adverse events, death, or other significant adverse events experienced by a patient during the course of a clinical trial. A patient narrative should provide a clinically relevant, chronological account of the event experienced during or immediately following a clinical study.
According to ICH guidelines, patient narratives are required to be included with the CSR. The primary consumers of these documents are Health Authorities, Safety Teams, and Data Safety Monitoring Boards.
Where do Patient Narratives go?
The location of patient narratives often depends on the volume. If narratives are fewer in number, they may be placed in the text of the CSR. Regardless, they eventually make their way into Module 5 of the eCTD folder structure for submissions.
Major challenges to authoring multiple patient narratives
Each narrative tells an individual patient story with data unique to that patient, and consistency is critical. However, authoring dozens – if not hundreds - of consistent patient narratives containing dozens of patient-specific datapoints takes a tremendous amount of time, despite teams almost always operating on a very narrow timeline.
Picture this: A team of 4 medical writers needs to produce 2000 patient narratives across multiple trials in a year. At 4 hours per document, that’s 8000 hours, and that breaks down to all four writers working full time year-round. Although theoretically possible, the only way for this to be possible is for zero rework to occur and to have no deadlines for submission timelines. So basically, it’s impossible.

What’s the risk of producing a high volume of patient narratives when deadlines are tight? Quality.
We’re only human, and that means mistakes are inevitable, regardless of the root cause being workload stress, fatigue, inattentional blindness, or even lack of familiarity with the source data. And that means the solution to reducing instances of human error is to automate through technology.
Sticking with tradition in producing patient narratives
Conventional medical writing typically starts in a tool like Microsoft Word by building a template that outlines the desired presentation of the patient narrative. But before a medical writing team can begin authoring a patient narrative, BioStats typically will need to create patient profiles first.
Traditionally, the data from patient profiles are then copied and pasted into a second document - the patient narrative - using the template created previously with Microsoft Word. This process entails a constant back and forth between BioStats and Medical Writing teams, generates additional work, creates opportunities to introduce errors, and adds to overall project timelines.
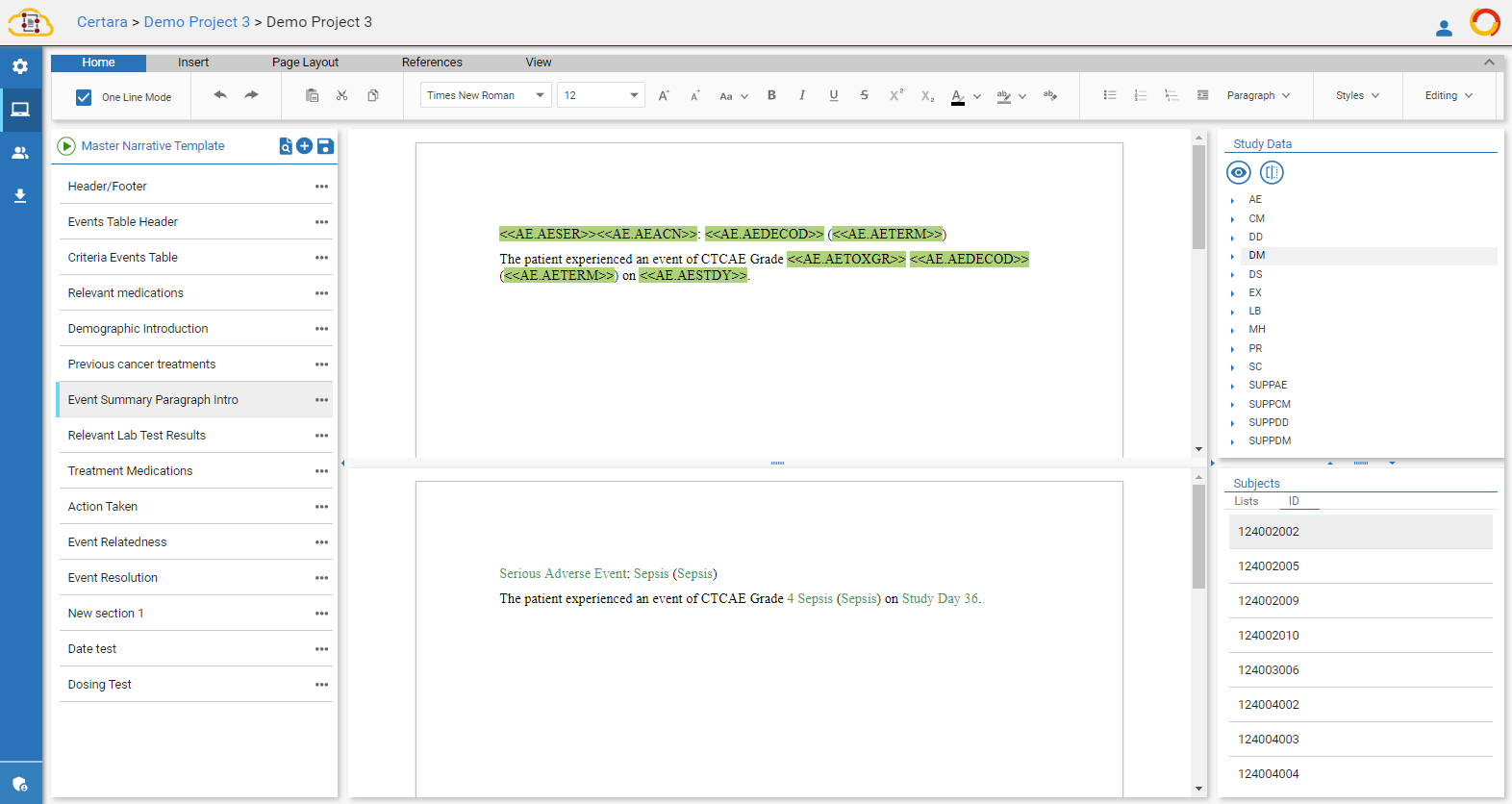
Another key element when producing hundreds of patient narratives across the study is consistency. Whether it’s the outline of the document, message development, presentation of information (i.e. dates), or formatting for all information throughout the patient narrative, consistency is essential. While human judgement is needed for key decision making like determining medical relevance, consistency remains elusive in manual input.
A major component of creating a consistent, compliant patient narrative is the ability to apply standard formatting to text, tables, and data variables. This is critical when working with SDTM data as formatting can vary dramatically from study to domain to variable. Prime examples in data variability include:
- fields in all caps
- fields that are abbreviated
- dates with various formats
The problem is that most medical writing teams don’t get to see any of the data until after database lock. That means it must be corrected manually, one instance at a time, in the Microsoft Word document.
Why produce draft documents from BioStats data before database lock?
It’s common for project stakeholders to be proactive and explore opportunities to prepare ahead and save time wherever possible. But why build a template using draft data pre-database-lock, especially if the data is bound to change eventually?
It is often helpful to create a template with test or draft data to provide the study lead with a preview of how the template will appear with actual study data before finalizing the template design and layout. As soon as draft SDTM datasets are available, they can be used to build a template and drive the discussion for template review and approval.
While the reasons for producing draft documents before database lock are convincing, many medical writing teams are siloed from the BioStats teams producing these SDTM datasets until after database lock.
Quality Control: Spot checking patient narratives in advance
Early access to draft datasets also aids medical writing teams in Quality Control measures.
When medical writers have the opportunity to work directly with the SDTM data, they have a better understanding of how the patient narrative should look, as well as an opportunity to “spot check” a live preview of the sample output. In the event a data domain or variable is missing, the medical writer can flag the data point, alter the presentation, or alert the BioStats team to the issue in question.
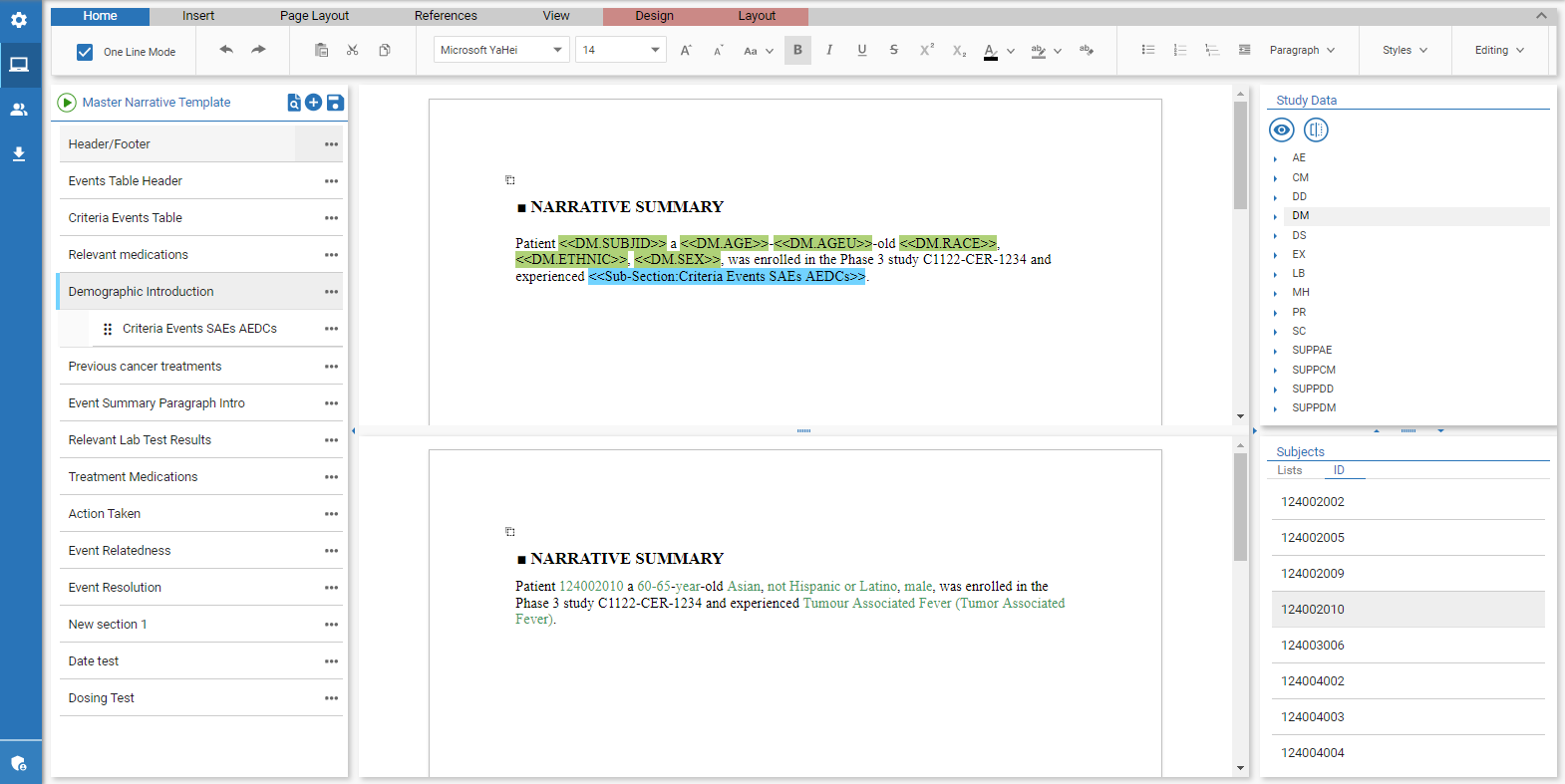
This live preview helps quickly identify if there are anomalies or abnormalities in the SDTM data . The best-case scenario is that a piece of data is simply poorly formatted, which can be addressed and corrected.
The worst case is missing or incomplete data. In this case, medical writers will have acted as an additional layer of data QC, which is especially helpful in the instance of working with pre-database lock SDTM datasets.
This live preview of patient specific values in the data allows the team to pinpoint the issue so that the team can trace back to the SDTM and source datasets to help identify the root cause.
The case for automation in medical writing
Organizations have begun to realize enormous gains due to the overall cost savings despite a dramatic uptick in productivity simply by adopting simple tech tools designed to assist in medical writing automation. These positive results can be attributed to five distinct reasons:
- Automation allows medical writers to produce hundreds of patient narratives with consistent presentation and layout, regardless of the variability in the underlying SDTM data. This helps improve overall quality and helps to ensure they are submission ready.
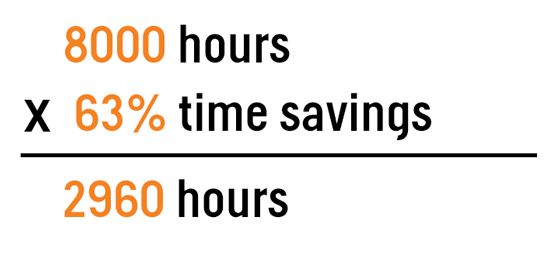
- Using SDTM data saves teams on average 63% more time versus traditional manual writing. Automating a majority of steps for both writing and QC can dramatically reduce effort while improving turnaround times.
- It allows medical writers to work directly with data. This enables full traceability of content and opens the door for medical writing teams to work ahead before the trial has concluded.
- Using validated SDTM files from BioStats further ensures data accuracy and quality of narratives produced.
- With the right automation tools and procedures, the need for patient profiles can be eliminated completely.
Let’s go back to our team of 4 medical writers producing 2000 patient narratives from earlier and apply the time savings reported above. That 8000 hours is now down to 2960.
Using SDTM data directly from BioStats to draft patient narratives has several tangible and intangible benefits, not the least of which is eliminating the need for patient profiles and giving time back to BioStats teams to do more constructive work.
Both Medical Writers and BioStats see this as a welcome trend; it eliminates many of the mundane and tedious steps in writing both patient profiles and patient narratives and empowers them to focus on relevance and key message development - areas where human intelligence is key.
Interested in more information on tools that can help your team automate labor-intensive medical writing tasks? Check out our recent webinar Quality SDTM - the Bridge between Biostats and Medical Writing for to see what we use to save time and create a strong ROI!
Tags:
Blog Main Page
