

4 Radnor Corporate Center
Suite 350
Radnor, PA 19087
+1 (888) 507-2270
中文论坛 (Chinese Language Forum)
Description
您可以用中文发言和提问。
March 2, 2022
嗨,请问透过P21自动产出的SDTM Spec或ADaM Spec,其内容是否需手动翻译为中文?
例如Date type = integer,翻译为整数值
December 10, 2021
Pinnacle 21 version 3.1.2
Engine Version: 2010.1
Configuration: SDTM-IG 3.2 (NMPA)
SDTM.AE数据集中AEDECOD的值已转换成中文字典编码(汉字),转为xpt后通过上述配置检查,出现ERROR SD0008 未能在MedDRA词典中找到AEDECOD的值。
请问可能是由于什么愿意导致的,谢谢!
November 8, 2021
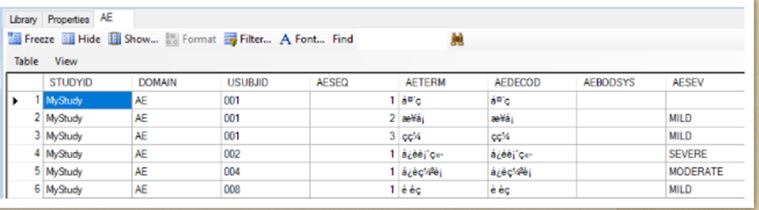
在SDTM.AE数据中相关的MedDRA coding变量的值已经在SAS数据集中做成中文,但是再转成xpt文件并用SASviewer软件打开后,所有中文显示为乱码(如下图)。
请问这种问题目前Pinnacle 21的NMPA engine会检查出来并且报告问题吗?并且这种情况是否能够满足NMPA的递交要求?如不能满足,是否有相关的解决方法?感谢!
August 13, 2021
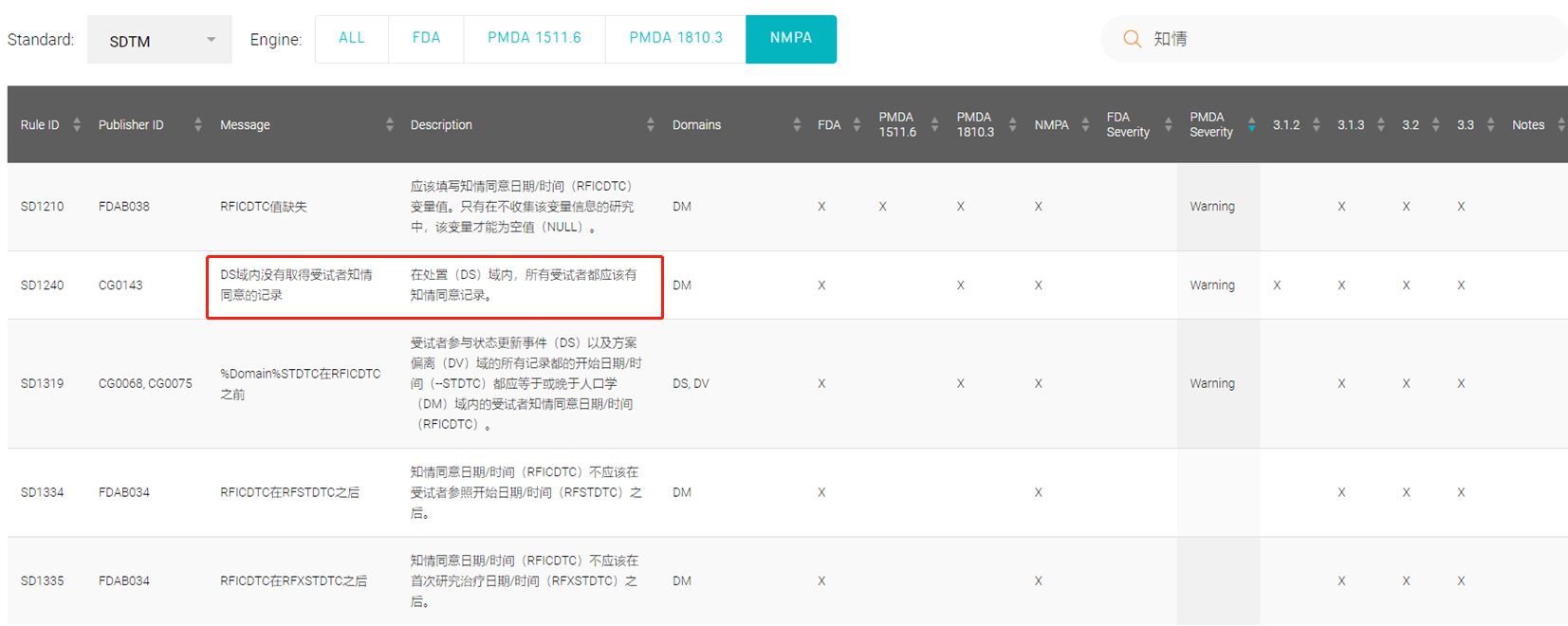
请问一下,DS中有知情同意的记录,但P21却报了 Message:DS域内没有取得受试者知情同意的记录?是什么原因导致?DSDECOD无法识别吗?是的话改用什么DSDECOD? 还是其他原因?如何解决?谢谢!
Subscribe to 中文论坛 (Chinese Language Forum)

